在 Go 语言中数组的长度固定,灵活性查,因此不常见到,而切片却无处不在,可以说是最为频繁的数据结构之一。
切片基于底层数组做了封装,它是底层数组的一个引用。切片具有以下特性。
- 切片是引用类型。是数组的一个引用,因此在作为参数传递时,它遵循引用传递类型;
- 切片内部由指向底层数组的指针、长度和容量三个要素组成;
- 切片的用法和数组类似,包括遍历、访问元素和获取长度等等;
- 切片的长度是可变的
1. 数据结构
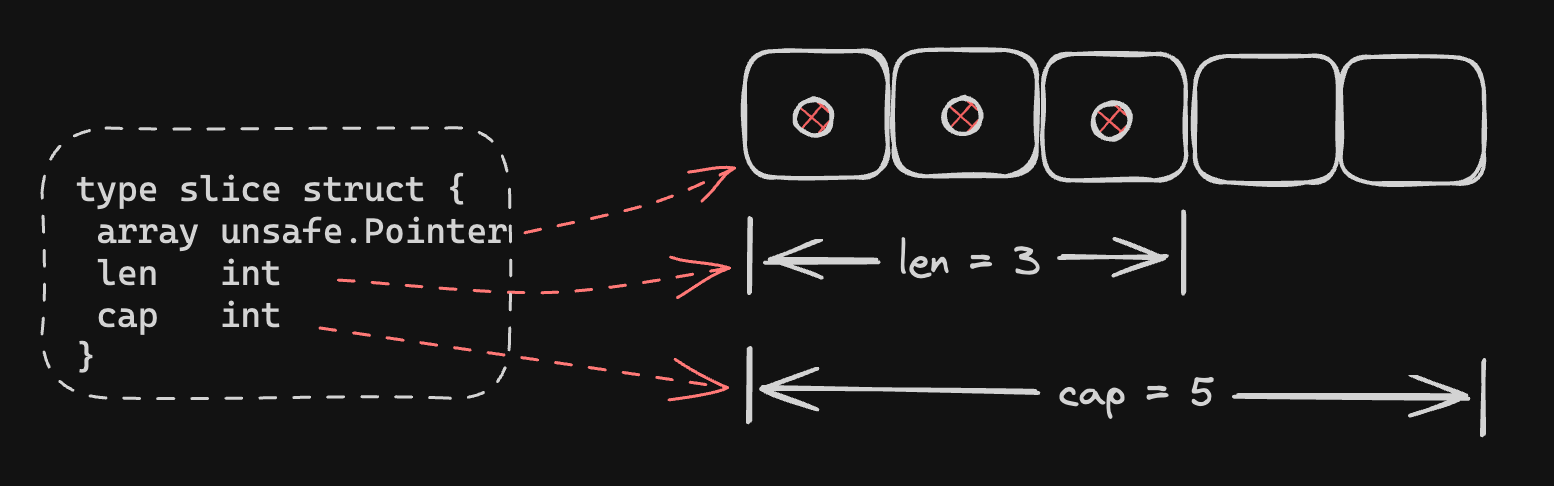
切片底层的数据结构是一个结构体,在 runtime/slice.go 中的定义如下:
type slice struct {
array unsafe.Pointer // 指向起点地址
len int // 长度
cap int // 容量
}- array:指向了内存空间地址的起点. 由于 slice 数据存放在连续的内存空间中,后续可以根据索引 index,在起点的基础上快速进行地址偏移,从而定位到目标元素
- len:切片的长度,指的是逻辑意义上 slice 中实际存放了多少个元素
- cap:切片的容量,指的是物理意义上为 slice 分配了足够用于存放多少个元素的空间. 使用 slice 时,要求 cap 永远大于等于 len
切片的下标不能超过 len,向后扩展时容量不能超过 cap 。多个切片可以共享底层数组,但起始位置、长度都可以不同。
通过 slice 数据结构定义可以看到,每个 slice 中存放的是内存空间的地址(array 字段),后续在传递切片的时候,相当于是对 slice 进行了一次值拷贝,但内部存放的地址是相同的,因此对于 slice 本身属于引用传递操作。
2. 初始化
2.1 声明但不初始化
下面给出的第一个例子,只是声明了 slice 的类型,但是并没有执行初始化操作,即 s 这个字面量此时是一个空指针 nil,并没有完成实际的内存分配操作。
var s []int 2.2 基于 make 进行初始化
make 初始化 slice 也分为两种方式
第一种方式如下:
s := make([]int,8)此时会将切片的长度 len 和 容量 cap 同时设置为 8. 需要注意,切片的长度一旦被指定了,就代表对应位置已经被分配了元素,尽管设置的会是对应元素类型下的零值。
第二种方式,是分别指定切片的长度 len 和容量 cap,代码如下:
s := make([]int,8,16)如上所示,代表已经在切片中设置了 8 个元素,会设置为对应类型的零值;cap = 16 代表为 slice 分配了用于存放 16 个元素的空间. 需要保证 cap >= len. 在 index 为[len, cap) 的范围内,虽然内存空间已经分配了,但是逻辑意义上不存在元素,直接访问会 panic 报数组访问越界;但是访问 [0,len) 范围内的元素是能够正常访问到的,只不过会是对应元素类型下的零值。
2.3 初始化连带赋值
初始化 slice 时还能一气呵成完成赋值操作. 如下所示:
s := []int{2,3,4}这样操作的话,会将 slice 长度 len 和容量 cap 均设置为 3,同时完成对这 3 个元素赋值。
2.4 初始化源码
下面我们来一起过目一下切片初始化的源码,方法入口位于 golang 标准库文件 runtime/slice.go 文件的 makeslice 方法中:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 根据每个元素的类型和 cap 计算消耗的总容量
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
// 检测乘法运算是否溢出 || 是否超出最大可分配内存 || 长度和容量是否合法
if overflow || mem > maxAlloc || len < 0 || len > cap {
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 分配内存,true 表示需要清零内存
return mallocgc(mem, et, true)
}上述方法核心步骤是
- 调用 math.MulUintptr 的方法,结合每个元素的大小以及切片的容量,计算出初始化切片所需要的内存空间大小
- 倘若内存空间超限,则直接抛出 panic
- 调用位于 runtime/malloc.go 文件中的 mallocgc 方法,为切片进行内存空间的分配
3. 引用传递与值传递
引用传递,指的是,将实例的地址信息传递到方法中,这样在方法中会直接通过地址追溯到实例所在位置,因此执行的一些修改操作会直接影响到原实例。
值传递,指的是对实例进行一轮拷贝,得到一个副本,然后将这个副本传递到方法中。这样在方法内部发生的修改动作都作用于这个副本之上,而副本本身和实例是相互独立的,因此不会影响到原实例。
func changeSlice(s []int) {
s[0] = 999
}
func main() {
s1 := []int{1, 2, 3}
changeSlice(s1)
fmt.Println(s1)
}[999 2 3]
将 main 方法中的切片 s1 作为 changeSlice 方法的入参传递,同时 changeSlice 内修改切片内的元素,这样会直接影响 main 方法中的切片 s1。 产生这个结果的原因就在于切片的传递是引用传递,而非值传递。
综上,每次我们在方法间传递切片时,会对 slice header 实例本身进行一次值拷贝,然后将 slice header 的副本传递到局部方法中。 然而,这个 slice header 副本中的 array 和原 slice 指向同一片内存空间,因此在局部方法中执行修改操作时,还会根据这个地址信息影响到原 slice 所属的内存空间,从而对内容发生影响。
4. 内容截取
除了👆上述数组初始化方法,还可以通过截取数组或切片来获取切片,截取的规则是左闭右开。
s[a:b],这里的 a 和 b 是可以缺省的。
-
如果 a 缺省不填则默认取 0 ,则代表从切片起始位置开始截取. 比如
s[:b]等价于s[0:b] -
如果 b 缺省不填,则默认取 len(s),则代表末尾截取到切片长度 len 的终点,比如
s[a:]等价于s[a:len(s)] -
a 和 b 均缺省也是可以的,则代表截取整个切片长度的范围,比如
s[:]等价于s[0:len(s)]
在对切片 slice 执行截取操作时,本质上是一次引用传递操作,因为不论如何截取,底层复用的都是同一块内存空间中的数据,只不过,截取动作会创建出一个新的 slice header 实例。
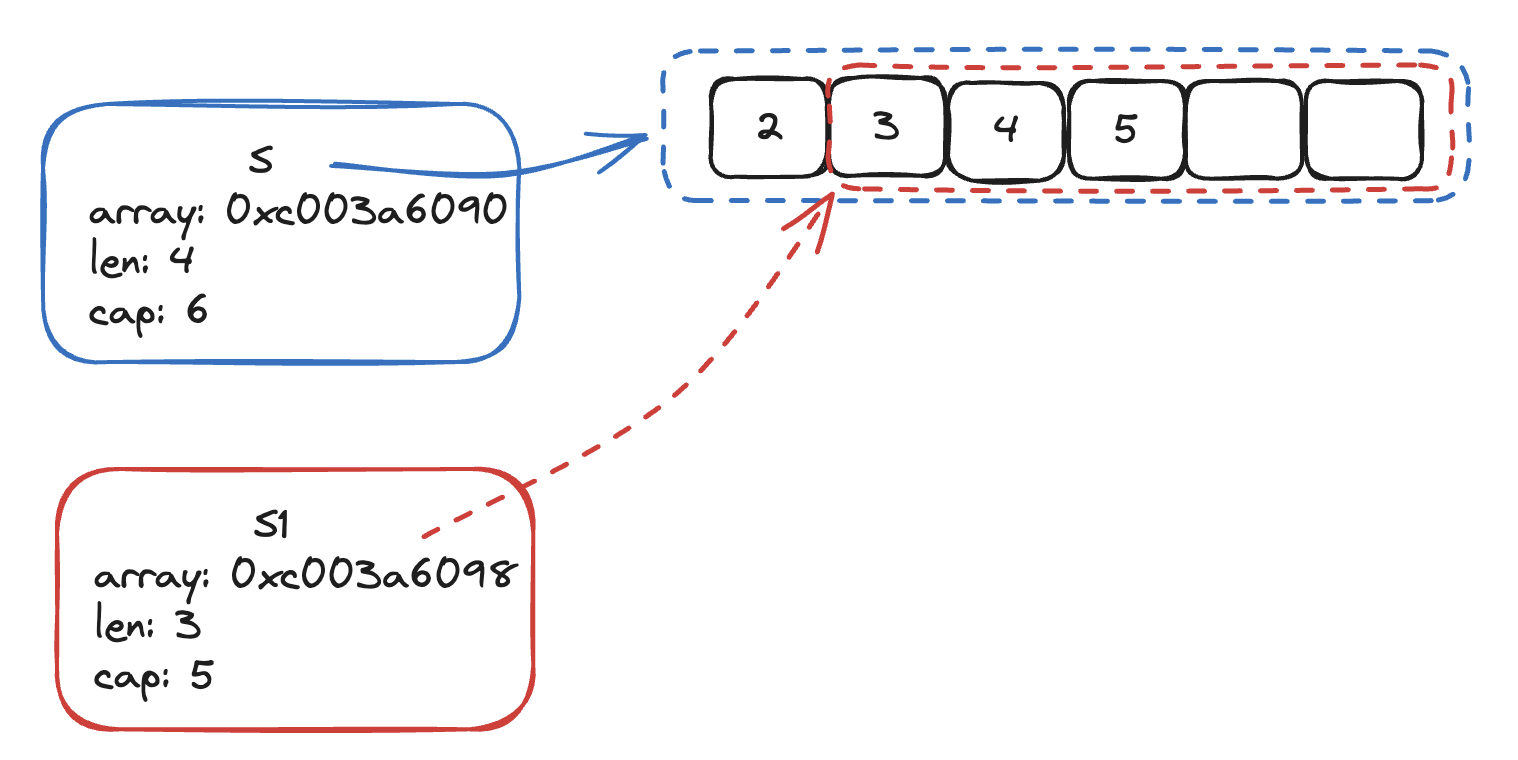
5. 元素追加
通过 append 操作,可以在 slice 末尾,额外新增一个元素. 需要注意,这里的末尾指的是针对 slice 的长度 len 而言. 这个过程中倘若发现 slice 的剩余容量已经不足了,则会对 slice 进行扩容。
s := []int{1, 2, 3}
s = append(s, 4)
// s [1, 2, 3, 4]下面是可能混淆 slice 中 len 和 cap 概念导致的错误:
func main() {
s := make([]int, 5)
for i := 0; i < 5; i++ {
s = append(s, i)
}
fmt.Println(s) // [0 0 0 0 0 0 1 2 3 4]
}可能我们预期多的是声明一个长度为 5 的 slice,向其中依次填入 0,1,2,3,4 五个元素,但是得到的结果却事与愿违,为什么?
- 通过 make 操作,声明了一个长度和容量均为 5 的切片 s,此前 5 个元素均被填充为零值 。
- 接下来执行 append 操作时,只会在长度末尾进行追加. 最终会引发扩容
对于我们的意图,可以使用如下两种方法:
- make 设置 len 为 0,cap 为 5。cap 和 len 之间的差值就是预留出来用于 append 操作的空间
func main() {
s := make([]int, 0, 5)
for i := 0; i < 5; i++ {
s = append(s, i)
}
fmt.Println(s) // [0 1 2 3 4]
}- 将 slice 的长度和容量都设置为 5,然后通过遍历 slice 的方式去相应的位置去复制,不用 append
func main() {
s := make([]int, 5)
for i := 0; i < 5; i++ {
s[i] = i
}
fmt.Println(s) // [0 1 2 3 4]
}我们在创建 slice 时,如果能够预估到其未来所需的容量空间,则应该提前分配好对应容量,避免在运行过程中频繁触发扩容操作,这样会对性能产生不利的影响。
6. 切片扩容
func main() {
s := []int{1, 2, 3, 4}
fmt.Printf("pointer=%p, len=%d, cap=%d\n", s, len(s), cap(s))
// pointer=0x14000134020, len=4, cap=4
s = append(s, 5)
fmt.Printf("pointer=%p, len=%d, cap=%d\n", s, len(s), cap(s))
// pointer=0x14000122040, len=5, cap=8
}当长度 4 的 slice 增加了一个元素后,底层指针变了,长度和容量也变了。那么扩容的机制是什么呢?扩容做了哪些操作呢?
6.1 源码
切片的扩容流程源码位于 runtime/slice.go 文件的 growslice 方法当中,其中核心步骤如下(下面版本是 go1.25.1):
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
// 计算旧长度并进行 sanity 检查
oldLen := newLen - num // 追加前的原始长度
if raceenabled {
callerpc := sys.GetCallerPC()
racereadrangepc(oldPtr, uintptr(oldLen*int(et.Size_)), callerpc, abi.FuncPCABIInternal(growslice))
}
if msanenabled {
msanread(oldPtr, uintptr(oldLen*int(et.Size_)))
}
if asanenabled {
asanread(oldPtr, uintptr(oldLen*int(et.Size_)))
}
// 如果 newLen 为负数,则 panic,因为切片长度不能为负
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
// 处理零大小元素
// 对于大小为零的类型(例如 struct{}),无需实际内存分配。返回一个指向全局零基地址(zerobase)的切片,长度和容量均为 newLen。这避免了不必要的分配,并确保非零长度时指针不为 nil。
if et.Size_ == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve oldPtr in this case.
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
// 计算新容量,
newcap := nextslicecap(newLen, oldCap)
// 计算内存大小并检查溢出
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.Size.
// For 1 we don't need any division/multiplication.
// For goarch.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
noscan := !et.Pointers()
switch {
case et.Size_ == 1: // 大小等于 1 ,无需乘法
lenmem = uintptr(oldLen)
newlenmem = uintptr(newLen)
capmem = roundupsize(uintptr(newcap), noscan) // 新容量的字节数,通过 roundupsize 向上取整以实现对齐和堆效率
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.Size_ == goarch.PtrSize: // 大小等于指针大小:使用移位或编译器优化的乘法
lenmem = uintptr(oldLen) * goarch.PtrSize
newlenmem = uintptr(newLen) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap)*goarch.PtrSize, noscan)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.Size_): // 2 的幂:使用位移进行乘法
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.TrailingZeros64(uint64(et.Size_))) & 63
} else {
shift = uintptr(sys.TrailingZeros32(uint32(et.Size_))) & 31
}
lenmem = uintptr(oldLen) << shift
newlenmem = uintptr(newLen) << shift
capmem = roundupsize(uintptr(newcap)<<shift, noscan)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
capmem = uintptr(newcap) << shift
default: // 默认:使用 math.MulUintptr 检测溢出
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem, noscan)
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\n")
// }
// 最终移除和分配限制检查
// 如果溢出或者分配超出限制,则 panic
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}
// 分配新内存
var p unsafe.Pointer
if !et.Pointers() {
p = mallocgc(capmem, nil, false) // 使用 mallocgc 上获取 capmem 字节
// The append() that calls growslice is going to overwrite from oldLen to newLen.
// Only clear the part that will not be overwritten.
// The reflect_growslice() that calls growslice will manually clear
// the region not cleared here.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in oldPtr since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
//
// It's safe to pass a type to this function as an optimization because
// from and to only ever refer to memory representing whole values of
// type et. See the comment on bulkBarrierPreWrite.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(oldPtr), lenmem-et.Size_+et.PtrBytes, et)
}
}
// 复制数据并返回
// 使用 memmove 将旧数据(lenmem 字节)复制到新指针(对重叠内存安全,尽管此处不需要)
memmove(p, oldPtr, lenmem)
// 返回新切片头。旧切片的后备数组如果不再引用,将被 GC 回收。
return slice{p, newLen, newcap}
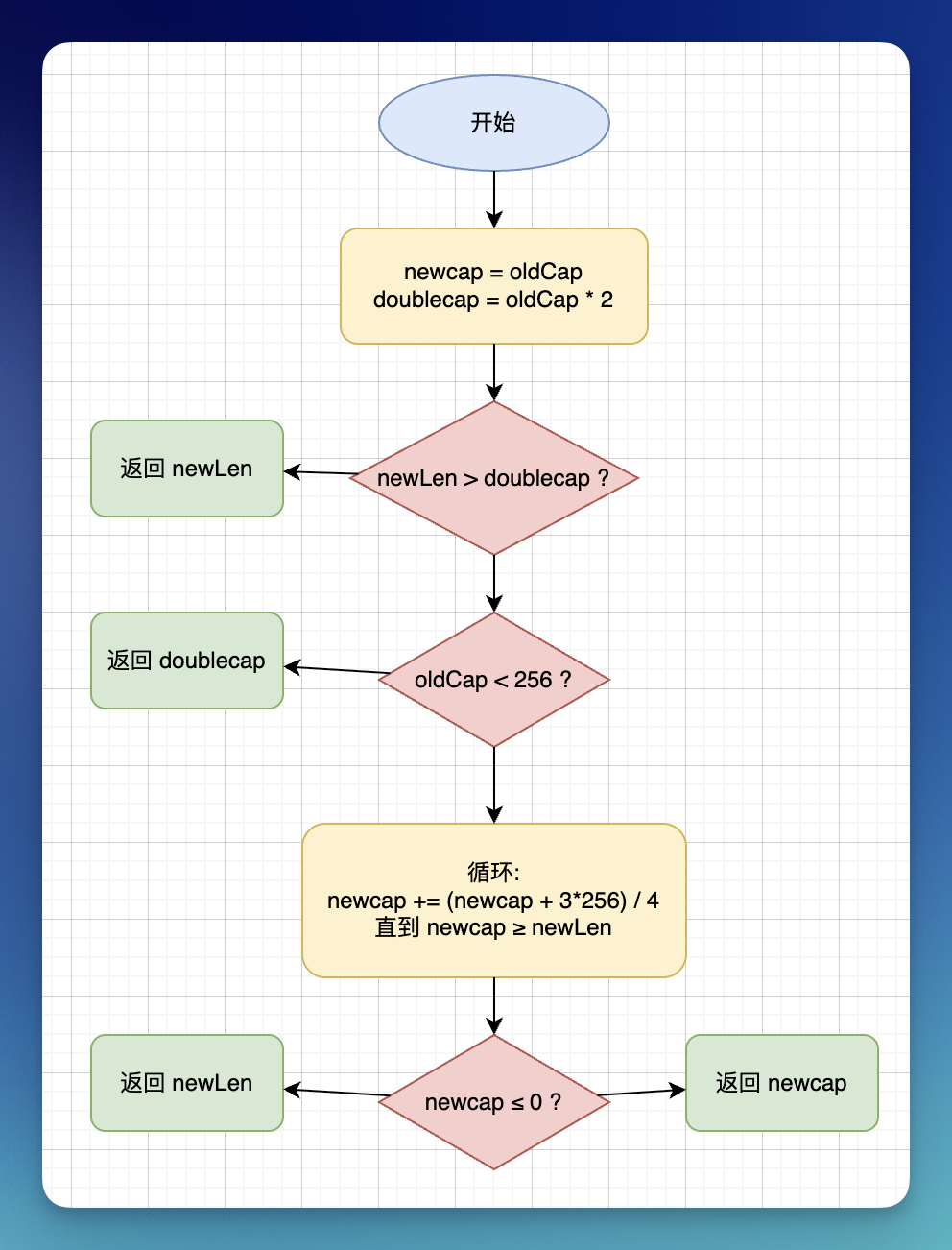
}func nextslicecap(newLen, oldCap int) int {
// 计算扩容后数组的容量
newcap := oldCap
// 取原容量两倍的容量数值
doublecap := newcap + newcap
// 如果新容量大于原容量的两倍,直接取新容量作为数组扩容后的容量
if newLen > doublecap {
return newLen
}
const threshold = 256
// 如果原容量小于 256,则扩容后新容量为原容量的两倍
if oldCap < threshold {
return doublecap
}
// 对于容量 >= 256 的切片,进入一个循环,逐步增加 newcap
for {
// 从小切片增长两倍过渡到大切片增长 1.25 倍,此公式可在两者之间实现较为平滑的过渡
// 等价于 (newcap + 3*256) / 4
newcap += (newcap + 3*threshold) >> 2
// 循环继续直到 newcap 满足 newcap >= newLen 或发生溢出
if uint(newcap) >= uint(newLen) {
break
}
}
// 处理溢出的情况
if newcap <= 0 {
return newLen
}
return newcap
}6.2 扩容总结
总结
- 直接返回新长度:如果
newLen > 2×oldCap,直接返回newLen - 小切片翻倍:如果
oldCap < 256,返回2×oldCap - 大切片渐进增长:如果
oldCap ≥ 256,使用公式newcap += (newcap + 3×256) / 4循环增长
对于大切片(≥256),每次迭代:
- 增长率 ≈ 1.25 倍(从 2 倍平滑过渡到 1.25 倍)
- 公式
(newcap + 3×256) / 4确保:- 容量较小时增长更快(接近 2 倍)
- 容量较大时增长放缓(接近 1.25 倍)
三种扩容策略详解
-
需求驱动(newLen > 2×oldCap)
// 示例: oldCap=10, newLen=30 // doublecap=20, newLen(30) > doublecap(20) // 直接返回 30,避免多次扩容
适用场景:一次性 append 大量元素
-
翻倍扩容(oldCap < 256)
// 示例: oldCap=100, newLen=150 // 100 < 256,返回 200优点:小切片快速增长,减少扩容次数
-
渐进增长(oldCap ≥ 256)
// 公式: newcap += (newcap + 3*256) / 4 // 等价于: newcap = newcap * 1.25 + 192 // 示例迭代过程: // oldCap=256, newLen=400 // 第1次: 256 + (256+768)/4 = 256 + 256 = 512 >= 400 ✓ // oldCap=1000, newLen=1200 // 第1次: 1000 + (1000+768)/4 = 1000 + 442 = 1442 >= 1200 ✓增长率变化:
- 容量 256 → 增长率接近 2.0x
- 容量 1024 → 增长率约 1.43x
- 容量越大 → 增长率越接近 1.25x
设计思想:
- 内存效率:大切片不再翻倍,避免浪费内存
- 性能权衡:小切片快速增长,减少分配次数
- 平滑过渡:256 作为阈值,实现增长策略的平滑切换
- 溢出保护:检测整数溢出,返回安全值
这种分段式扩容策略是 Go 1.18+ 版本的优化设计,相比旧版本的简单翻倍策略更加智能和高效!
增长公式
newcap += (newcap + 3*256) / 4
```
newcap_new = newcap_old + (newcap_old + 768) / 4
= newcap_old × 1.25 + 192
```1.25 倍不是固定的增长率! 正确的公式是:newcap_new = newcap_old × 1.25 + 192
| oldcap | 计算过程 | newcap | 增长速度 |
|---|---|---|---|
| 256 | 256×1.25+192 | 512 | 2.0🚀 |
| 512 | 512×1.25+192 | 832 | 1.625🚀 |
| 1000 | 1000×1.25+192 | 1442 | 1.442🚀 |
| 10000 | 10000×1.25+192 | 12692 | 1.269🚀 |
| 100000 | 100000×1.25+192 | 125192 | 1.252🚀 |
- 容量越大,192 的影响越小
- 最终增长率趋近于 1.25
7. 元素删除
从切片中删除元素的实现思路,本质上和切片内容截取的思路是一致的.
如果需要删除开头或者末尾的元素:
func main() {
s := []int{1, 2, 3, 4, 5}
// 删除首个元素
s = s[1:] // [2 3 4 5]
// 删除末尾元素
s = s[:len(s)-1] // [2 3 4]
}如果需要删除 slice 中间某个元素,操作思路则采用截取加上元素追加的符合操作,可以先截取待删除元素的左侧部分内容,然后在此基础上追加上待删除元素后侧部分的内容:
func main() {
s := []int{1, 2, 3, 4, 5}
// 删除 index = 2 的元素
s = append(s[:2], s[3:]...)
fmt.Printf("%v, len: %d, cap: %d\n", s, len(s), cap(s))
// [1 2 4 5], len: 4, cap: 5
}如果需要删除 slice 中的所有元素可以这样做:
func main() {
s := []int{1, 2, 3, 4, 5}
s = s[:0]
fmt.Printf("s: %v, len:%d, cap:%d\n", s, len(s), cap(s))
// s: [], len:0, cap:5
}slice header 中的指针 array 仍指向远处,但是逻辑意义上其长度 len 已经等于 0,而容量 cap 则仍保留为原值
8. 切片拷贝
拷贝可以分为简单拷贝和完整拷贝两种类型. 简单拷贝 : 要实现简单拷贝,我们只需要对切片的字面量进行赋值传递即可,这样相当于创建出了一个新的 slice header 实例,但是其中的指针 array、容量 cap 和长度 len 仍和老的 slice header 实例相同.
func main() {
s := []int{1, 2, 3, 4, 5}
s1 := s
fmt.Printf("s 的地址:%p, s1的地址:%p\n", s, s1)
// s 的地址:0x140000181b0, s1的地址:0x140000181b0
}这里再声明一下,切片的截取操作也属于是简单拷贝,以下面操作代码为例,s 和 s1 会使用同一片内存空间,只不过地址起点位置偏移了一个元素的长度. s1 和 s 的地址,刚好相差 8 个 byte.
func main() {
s := []int{1, 2, 3, 4, 5}
s1 := s[1:]
fmt.Printf("s 的地址:%p, s1的地址:%p\n", s, s1)
// s 的地址:0x140000ba000, s1的地址:0x140000ba008
}slice 的完整复制,指的是会创建出一个和 slice 容量大小相等的独立的内存区域,并将原 slice 中的元素一一拷贝到新空间中. 在实现上,slice 的完整复制可以调用系统方法 copy,代码示例如下,通过日志打印的方式可以看到,s 和 s1 的地址是相互独立的:
func main() {
s := []int{1, 2, 3, 4, 5}
s1 := make([]int, len(s))
copy(s1, s)
fmt.Printf("s:%v, s1:%v\n", s, s1)
// s:[1 2 3 4 5], s1:[1 2 3 4 5]
fmt.Printf("s的地址:%p, s1的地址:%p\n", s, s1)
// s的地址:0x1400012a000, s1的地址:0x1400012a030
}9. 易错面试题
-
考察初始化、扩容
func Test_slice(t *testing.T) { s := make([]int, 10) s = append(s, 10) t.Logf("s: %v, len of s: %d, cap of s: %d", s, len(s), cap(s)) // s: [0 0 0 0 0 0 0 0 0 0 10], len of s: 11, cap of s: 20 }基于 make([]int, 10) 的方式初始化切片的话其长度 len 和容量 cap 均为 10,且前10个元素是已经切实被分配过的(虽然会被填充为零值)。此时进行 append 操作,会在末尾进行元素追加,由于切片的长度和容量是相等的,因此已经没有剩余可用的空间了,于是会进一步引发切片的扩容操作。
-
考察 make 初始化
func Test_slice(t *testing.T) { s := make([]int, 0, 10) s = append(s, 10) t.Logf("s: %v, len of s: %d, cap of s: %d", s, len(s), cap(s)) // s: [10], len of s: 1, cap of s: 10 }make([]int, 0, 10) 的方式使得切片长度为 0,容量为 10,实际上还有长度为 10 的缓存空间. 于是这一次 append 操作,会直接使用已有的空间,不会引发扩容. 结果中,切片长度从 0 增加为 1,容量则维持为 10 不变.
-
考察扩容
func Test_slice(t *testing.T){ s := make([]int,10) s = append(s,10) t.Logf("s: %v, len of s: %d, cap of s: %d",s,len(s),cap(s)) // s: [0 0 0 0 0 0 0 0 0 0 10], len of s: 11, cap of s: 11 }由于容量大于长度,因此仍有足够的空间,这次 append 操作不会引发扩容.
-
考察 slice 截取
func Test_slice(t *testing.T) { s := make([]int, 10, 12) s1 := s[8:] t.Logf("s1: %v, len of s1: %d, cap of s1: %d", s1, len(s1), cap(s1)) // s1: [0 0], len of s1: 2, cap of s1: 4 }截取操作会以 s[8] 作为内存空间的起点,截取所得新切片 s1 的长度和容量强依赖于原切片 s 的长度和容量,并在此基础上减去头部 8 个未使用到的单位。
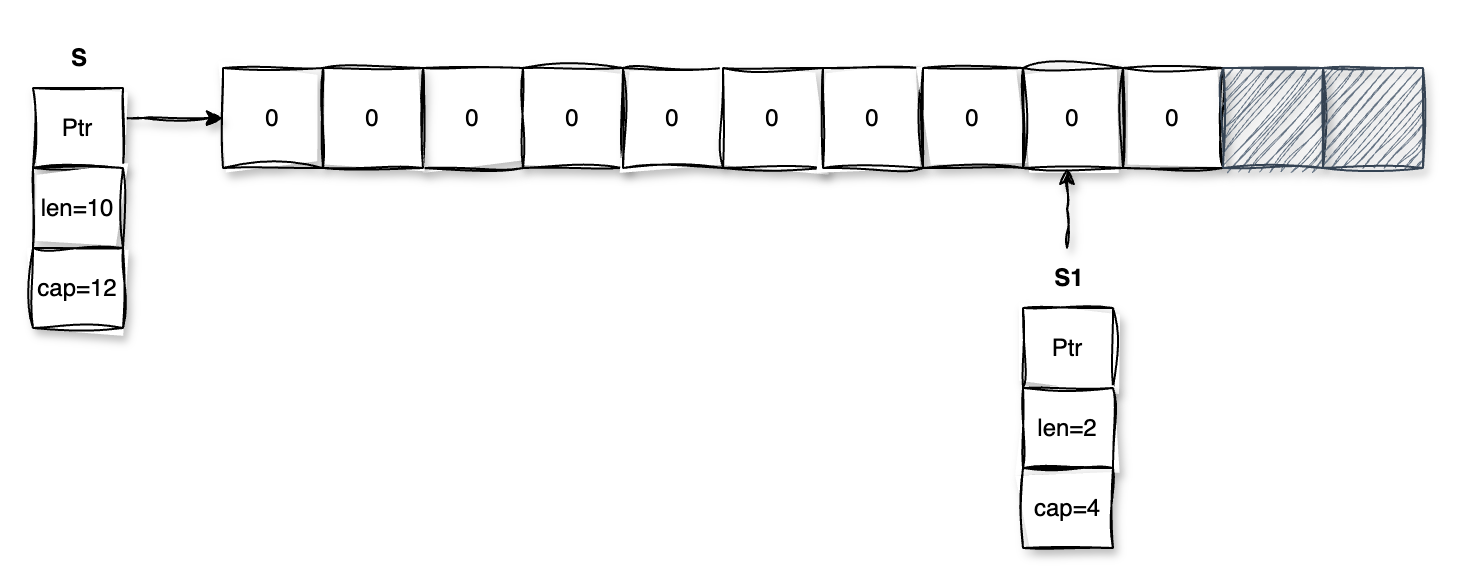
-
考察 slice 截取
func Test_slice(t *testing.T) { s := make([]int, 10, 12) s1 := s[8:9] t.Logf("s1: %v, len of s1: %d, cap of s1: %d", s1, len(s1), cap(s1)) // s1: [0], len of s1: 1, cap of s1: 4 }与问题 4 相似,考察了截取的右边界。
-
slice 底层数据结构
func Test_slice(t *testing.T) { s := make([]int, 10, 12) s1 := s[8:] s1[0] = -1 t.Logf("s: %v", s) // s: [0 0 0 0 0 0 0 0 -1 0] }s1 是在 s 基础上截取得到的,属于一次引用传递,底层共用同一片内存空间,其中 s[x] 等价于 s1[x+8]. 因此修改了 s1[0] 会直接影响到 s[8] 。
-
数组越界问题
func Test_slice(t *testing.T) { s := make([]int, 10, 12) v := s[10] // 求问,此时数组访问是否会越界 }会发生 panic。
初始化时设定了切片长度为10,容量为 12. 容量是物理意义上的,但长度是逻辑意义上的,判断是否越界以逻辑意义为准,因此 index = 10 已经越界。
-
数组越界问题
func Test_slice(t *testing.T){ s := make([]int,10,12) s1 := s[8:] s1 = append(s1,[]int{10,11,12}...) v := s[10] // ... // 求问,此时数组访问是否会越界 }会发生 panic
- 在 s 的基础上截取产生了 s1,此时 s1 和 s 会拥有两个独立的 slice header.
- 接下来执行 append 操作时,由于 s 预留的空间不足,s1 会发生扩容
- s1 扩容后,会被迁移到新的空间地址,此时 s1 已经和 s 做到真正意义上的完全独立,意味着修改 s1 不再会影响到 s
- s 继续维持原本的长度值 10 和容量值 12,因此访问 s[10] 会panic
-
传递问题
func Test_slice(t *testing.T){ s := make([]int,10,12) s1 := s[8:] changeSlice(s1) t.Logf("s: %v",s) // s: [0 0 0 0 0 0 0 0 -1 0] } func changeSlice(s1 []int){ s1[0] = -1 }切片在传递时属于引用传递,且 s1[0] 和 s[8] 指向同一个元素. 因此在局部方法中,修改了 s1[0] 会直接影响到 s[8] 的内容.
-
传递问题
func Test_slice(t *testing.T) { s := make([]int, 10, 12) s1 := s[8:] changeSlice(s1) t.Logf("s: %v, len of s: %d, cap of s: %d", s, len(s), cap(s)) t.Logf("s1: %v, len of s1: %d, cap of s1: %d", s1, len(s1), cap(s1)) } func changeSlice(s1 []int) { s1 = append(s1, 10) }结果:
s: [0 0 0 0 0 0 0 0 0 0], len of s: 10, cap of s: 12 s1: [0 0], len of s1: 2, cap of s1: 4虽然切片是引用传递,但是在方法调用时,传递的会是一个新的 slice header。 因此在局部方法 changeSlice 中,虽然对 s1 进行了 append 操作,但这这会在局部方法中这个独立的 slice header 中生效,不会影响到原方法 Test_slice 当中的 s 和 s1 的长度和容量。
-
越界问题
func Test_slice(t *testing.T) { s := []int{0, 1, 2, 3, 4} s = append(s[:2], s[3:]...) t.Logf("s: %v, len: %d, cap: %d", s, len(s), cap(s)) v := s[4] // 是否会数组访问越界 }s: [0 1 3 4], len: 4, cap: 5会发生 panic
执行完上述 append 操作之后,s 的实际长度为 4,容量维持不变为 5. 此时访问 s[4]会发生数组越界的错误。
底层数组变成了这样:
index: 0 1 2 3 4 value: [0 | 1 | 3 | 4 | 4] slice: ↑-----------↑ len=4, cap=5 -
切片扩容问题
func Test_slice(t *testing.T) { s := make([]int, 512) s = append(s, 1) t.Logf("len of s: %d, cap of s: %d", len(s), cap(s)) // 513, 848 }由于切片 s 原有容量为 512,已经超过了阈值 256,因此对其进行扩容操作会采用的计算共识为 512 * (512 + 3*256)/4 = 832
其次,在真正申请内存空间时,我们会根据切片元素大小乘以容量计算出所需的总空间大小,得出所需的空间为 8byte * 832 = 6656 byte
再进一步,结合分配内存的 mallocgc 流程,为了更好地进行内存空间对其,golang 允许产生一些有限的内部碎片,对拟申请空间的 object 进行大小补齐,最终 6656 byte 会被补齐到 6784 byte 的这一档次. (内存分配时,对象分档以及与 mspan 映射细节可以参考 golang 标准库 runtime/sizeclasses.go 文件)
// class bytes/obj bytes/span objects tail waste max waste min align // 1 8 8192 1024 0 87.50% 8 // 2 16 8192 512 0 43.75% 16 // 3 24 8192 341 8 29.24% // ... // 48 6528 32768 5 128 6.23% 128 // 49 6784 40960 6 256 4.36% 128再终,在 mallocgc 流程中,我们为扩容后的新切片分配到了 6784 byte 的空间,于是扩容后实际的新容量为 cap = 6784/8 = 848.
10. 总结
-
slice 是一个长度可变的连续数据序列,在实现上基于一个 slice header 组成,其中包含的字段包括:指向内存空间地址起点的指针 array、一个表示了存储数据长度的 len 和分配空间长度的 cap
-
由于 slice 在传递过程中,本质上传递的是 slice header 实例中的内存地址 array,因此属于引用传递
-
slice 在扩容时,遵循如下机制:
• 如果扩容时预期的新容量超过原容量的两倍,直接取预期的新容量
• 如果原容量小于 256,直接取原容量的两倍作为新容量
• 如果原容量大于等于 256,在原容量 n 的基础上循环执行 n += (n+3 * 256)/4 的操作,直到 n 大于等于预期新容量,并取 n 作为新容量
- slice 不是并发安全的数据结构,大家在使用时请务必注意并发安全问题。
-